Vertical Slice Architecture in .NET 10: The Ultimate Guide (2026)
Based on the template with 540+ GitHub stars, this guide shows you how to ditch the layers, organize by feature, and ship faster in .NET 10
I am hands-on Software Architect and Tech Lead with over 17 years of experience designing, developing and deploying various commercial software architectures on the full stack.
I shared a GitHub template for Vertical Slice Architecture back in 2022. It reached more then 500 stars and helped developers move past the rigidity of Clean Architecture.
But tools change. .NET 10 and C# 14 make vertical slices cleaner and easier to write. I updated my approach for 2026. This guide shows you how to organize a monolith for speed.
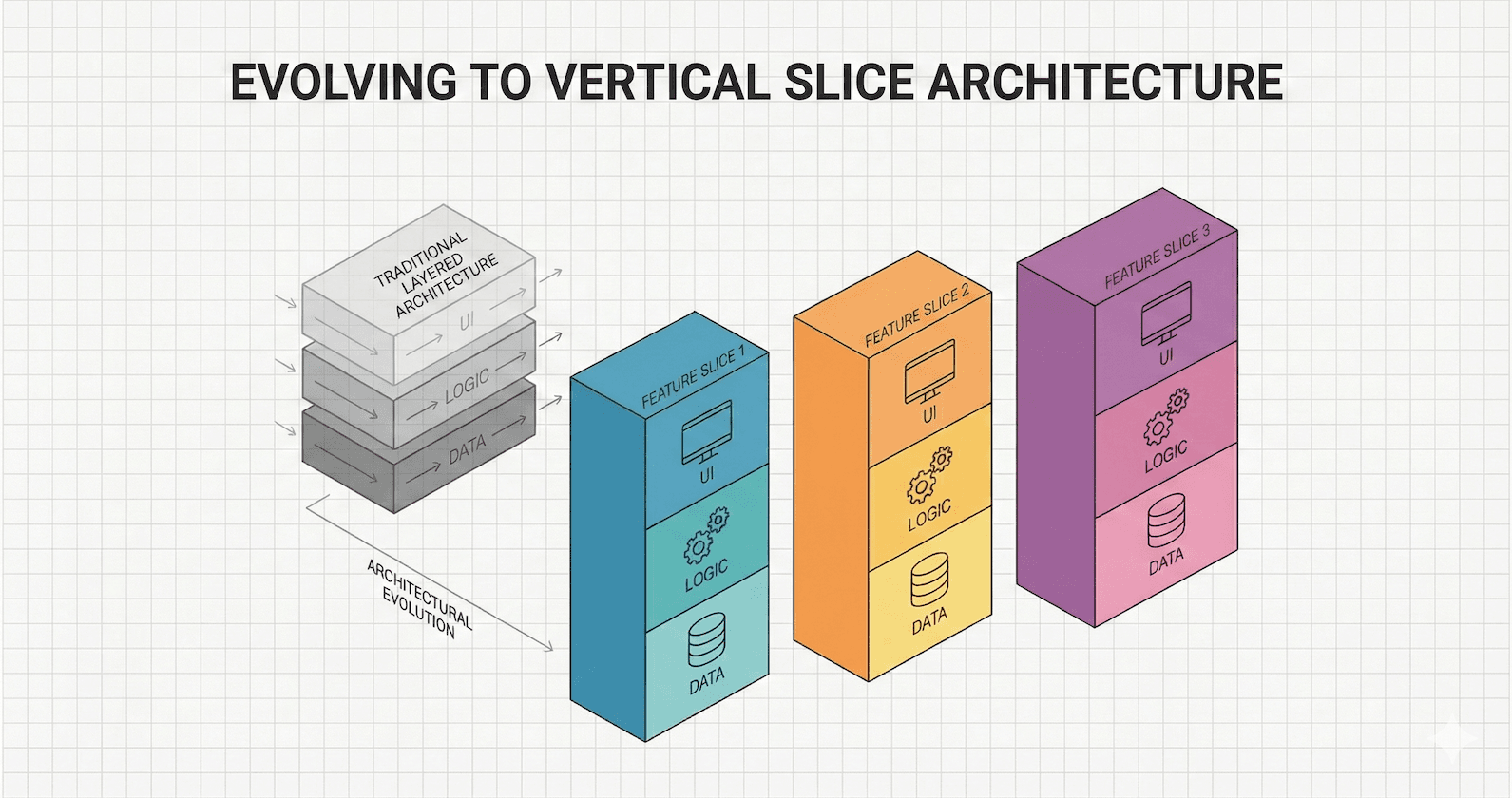
Traditional Layered Architecture
The first approach is the traditional layered architecture. This is a very common way to organize code and has been a standard for decades. I’m sure you have seen and used this on many projects before. A traditional layered/onion architecture approach organizes code around technical concerns in layers. In this approach, different layers are defined based on their responsibilities in the system. The layers then depend on each other so that they can collaborate and achieve their responsibilities. The dependency flow is guaranteed by forcing each layer to only depend on the ones below them (e.g., the presentation layer can only call code in the business logic layer).
For example, in a web application, we might define these four layers:
Presentation Layer (controllers)
Business Logic Layer (services)
Data Access Layer (repositories)
Infrastructure Layer (database)
The Problem with a traditional layered architecture
The most significant drawback of a layered architecture is that each layer is highly coupled to the layers it depends on. This coupling makes a layered architecture rigid and difficult to maintain.
The tight coupling also makes it more difficult for developers working on different parts of the application to make changes in parallel, because one developer's work might cause problems with another developer's work. Having tight coupling between the layers, when changes are made to a feature, all the layers must be changed.
Typically if I need to change a feature in a layered application, I end up touching different layers of the application and navigating through piles of projects, folders and files. For example for a simple change in a given feature, you could be editing more than 5 files in all the layers:
Domain/TodoItem.csRepositories/TodoItemsRepository.csServices/TodoItemsService.csViewModels/TodoItemsViewModel.csControllers/TodoItemsController.cs
Layered architecture is great for some things, but it does have major drawbacks:
Tight coupling between layers. You can't easily swap out a layer without rewriting code in other layers. This means that if you want to make a change to one feature, you might have to touch several different layers.
Each layer is aware of the next layer down (and sometimes even a few more). This makes it very difficult to understand the "big picture" at any given time and can lead to unexpected side effects when we make changes in one part of our application.
It's often unclear where some components belong; should they be placed in Business Logic or Data Access? Do they go in both? Or maybe in the Presentation as well? These are questions that we need answers to before writing any code or else we will end up with big messes of tightly coupled spaghetti code.
Instead of separating based on technical concerns, Vertical Slices are about focusing on features.
Vertical Slice Architecture
Implementing a vertical slice architecture is a good step in designing a robust software system. It's important to be familiar with it because it provides the foundation for how to structure your codebase and establish the roles and responsibilities of each part of your application.
First, let's clarify what vertical slice architecture means. A vertical slice is an architectural pattern that organizes your code by feature instead of organizing by technical concerns. For example, you can have different features for creating an admin user account versus a normal user account. Or you could have different features for checking if something has been created versus an existing item. This method helps keep track of exactly what your application does for a particular use case within the application.
It's about the idea of grouping code according to the business functionality and putting all the relevant code close together. It improves maintenance, testability, and clean separation of concerns and is easier to adapt to changes.
The Vertical Slice architecture approach is a good starting point that can be evolved later when an application becomes more sophisticated:
We can start simple (Transaction Script) and simply refactor to the patterns that emerge from code smells we see in the business logic.
- Jimmy Bogard.
Vertical Slice vs. Clean Architecture: Key Differences
While Clean Architecture emphasizes horizontal layers (UI, Application, Domain, Infrastructure), Vertical Slice Architecture emphasizes features.
| Feature | Clean Architecture (Layers) | Vertical Slice Architecture |
|---|---|---|
| Primary Unit | Layers (Projects) | Features (Slices) |
| Coupling | High logical coupling within layers | Low coupling between features |
| Code Sharing | Encouraged (Shared Services) | Discouraged (Duplicate > Wrong Abstraction) |
| Change Impact | Touches multiple projects/files | Contained within one slice |
| Best For | Enterprise standardization | Rapid development & Domain complexity |
For a deeper comparison including migration strategies, hybrid approaches, and team-based recommendations, see Vertical Slice vs. Clean Architecture: Which Should You Choose?
Looking for folder organization patterns? See the VSA folder structure guide comparing 4 different approaches.
Example Vertical Slice Architecture Project solution in C# .NET 9
Most applications start simple but they tend to change and evolve. Because of this, I wanted to create a simpler example project template that showcases the Vertical Slice Architecture approach.
The goal is to stop thinking about horizontal layers and start thinking about vertical slices and organize code by Features. When the code is organized by feature you get the benefits of not having to jump around projects, folders and files. Things related to given features are placed close together.
When moving toward the vertical slices we stop thinking about layers and abstractions. The reason is the vertical slice doesn't necessarily need shared layer abstractions like repositories, services and controllers. We are more focused on concrete Feature implementation and what is the best solution to implement. With this approach, every Feature (vertical slice) is in most cases self-contained and not coupled with other slices. The features relate and share the same domain model in most cases.

The change from Clean Architecture to Vertical Slice Architecture
This project repository is created based on the Clean Architecture solution template by Jason Taylor, and it uses technology choices and application business logic from this template, like:
ASP.NET API with .NET 9
CQRS with MediatR
FluentValidations
EF Core 9
xUnit, FluentAssertions, Moq
Result pattern for handling exceptions and errors using
I used the Clean Architecture template because it uses the CQRS pattern with the MediatR library and vertical slices naturally fit into the commands and queries.
nother approach I took (taken from Derek Comartin) about organizing code, is to put all code related to a given feature in a single file in most cases. With this approach we are having self-explanatory file names BookAppointment.cs and all related code close together: Api controller action methods, MediatR requests, MediatR handlers, validations, and DTOs. This is what it looks like:
public static class BookAppointment
{
public record Command(
Guid PatientId,
Guid DoctorId,
DateTimeOffset Start,
DateTimeOffset End,
string? Notes) : IRequest<ErrorOr<Result>>;
public record Result(Guid Id, DateTime StartUtc, DateTime EndUtc);
internal sealed class Validator : AbstractValidator<Command>
{
public Validator()
{
RuleFor(v => v.PatientId).NotEmpty();
RuleFor(v => v.DoctorId).NotEmpty();
RuleFor(v => v.Start).LessThan(v => v.End)
.WithMessage("Start time must be before end time");
RuleFor(v => v.Start)
.Must(start => start > DateTimeOffset.UtcNow.AddMinutes(30))
.WithMessage("Appointment must be scheduled at least 30 minutes in advance");
}
}
internal sealed class Handler(ApplicationDbContext context)
: IRequestHandler<Command, ErrorOr<Result>>
{
public async Task<ErrorOr<Result>> Handle(Command request, CancellationToken ct)
{
var startUtc = request.Start.UtcDateTime;
var endUtc = request.End.UtcDateTime;
// Check for overlapping appointments
var hasConflict = await context.Appointments
.AnyAsync(a => a.DoctorId == request.DoctorId
&& a.Status == AppointmentStatus.Scheduled
&& a.StartUtc < endUtc && a.EndUtc > startUtc, ct);
if (hasConflict)
return Error.Conflict("Appointment.Conflict",
"Doctor has a conflicting appointment");
// Domain factory method enforces invariants and raises domain events
var appointment = Appointment.Schedule(
request.PatientId, request.DoctorId, startUtc, endUtc, request.Notes);
context.Appointments.Add(appointment);
await context.SaveChangesAsync(ct);
return new Result(appointment.Id, appointment.StartUtc, appointment.EndUtc);
}
}
}
Want step-by-step setup instructions? See the Quick Start Guide to clone, configure, and run the template in minutes.
Vertical Slice Architecture and Clean Architecture
For a detailed comparison between two prominent approaches of organizing code check this blog post from NDepend where Clean Architecture is compared to Vertical Slice Architecture and Vertical Slice Architecture template .NET.
Why Vertical Slices Work
Moving to a feature-first mindset fixes specific pain points for growing teams.
Faster Delivery. You keep all code for a feature in one place. You build, test, and ship without getting tangled in shared layers. You get business value out the door quicker.
Easier Maintenance. Co-locating code reduces cognitive load. You don't have to hunt through five different projects to trace how a single button works. It’s all right there.
Safer Changes. Slices stay isolated. You can change one feature without the risk of breaking an unrelated part of the app. Your team gains the confidence to deploy more often.
Intuitive Codebase. The folder structure matches the business capabilities. A new developer can look at the project and immediately understand what the application actually does.
The Trade-offs
VSA isn't a magic fix. It relies heavily on discipline.
The flexibility is both the biggest strength and the biggest risk. As Jimmy Bogard notes, VSA "does assume that your team understands code smells and refactoring."
If you ignore this, you invite chaos. The risk of code duplication turns into reality fast. You have to actively manage shared logic. If your team doesn't know how to spot code smells, you will lose the benefits of the architecture entirely.
| Benefit | Corresponding Challenge / Trade-off |
|---|---|
| Feature Isolation & Speed | Potential for Code Duplication: Without careful management, common logic (like validation or mapping) might be repeated across different slices. |
| Implementation Flexibility | Risk of Inconsistency: Each slice can solve problems differently. Without team discipline and good code reviews, this can lead to inconsistent patterns across the application. |
| Reduced Abstractions | Requires Stronger Refactoring Skills: Since there are fewer mandatory layers, developers must be skilled at identifying code smells and refactoring complex logic inside a handler to keep it clean and maintainable. |
Example Vertical Slice Architecture project solution source code
Check out my source code Vertical Slice Architecture Template for more info. If you like this please give a star to the repository :).
Related Reading
This article is part of the Vertical Slice Architecture Series:
Vertical Slice vs. Clean Architecture: Which Should You Choose? — Detailed comparison with real code examples, migration strategies, and decision framework
VSA Folder Structure: 4 Approaches Compared — How to organize your feature folders for maintainability
Getting Started Guide — Clone, configure, and run the template in minutes
Source Code: Vertical Slice Architecture Template on GitHub (540+ stars)